

How to catch a Pokemon with Object Detection — a fun example of Deep Learning
- Feb 16, 2021
- 6 min read
Updated: Mar 7
What if we could understand how computers think? And what if we could have fun doing it?
Many of us have had a little more time to go deeper in our thinking, possibly even have time for side projects. As we reflect on lessons we can learn from the world around us, and where we want to explore new areas with data science and AI, we have been reviewing some high level concepts and wanted to share a fun little project. This is not aimed for mathematical rigorousness, but more aimed to demonstrate how data scientists and data science enthusiasts can build intuition. Read to the end to download the code and sample data package.
How artificial intelligence learns?
AI kind of learns similarly as a human. Let's use Pokemon as an example. When a child plays the game, they look at a visual, for example, a Pikachu, and someone or something tells what it is -- it is a Pikachu, not a Charmander. They learn incredibly fast by accepting both the visual information and the text, which can be via sound. Next time they see another Pikachu, they know what it is, even it might be represented differently, for example, as a pixelated image.
AI learns in a similar way today. The AI uses a camera for its eyes, and with the corresponding image, it receives a set of text, which often follows a specific format. The image below shows such an example.
The image on the right is what AI "sees", and the xml file on the left tells the AI what the images are. The blue part in the file shows what the object is -- it is a Squirtle, and where it is -- it is within something called the "bounding box", as the blue rectangle on the image, and the location is denoted by the coordinates. In this example, the xmin and ymin locate the upper-left corner and the xmax and ymax locate the bottom-right corner of the bounding box.

After the AI "sees" many of such images with the labels, it then "learns". Next time, when an image comes in without any of these bounding boxes and labeling files, the AI will be able to locate where the objects are, and classify what they are. This leads to what defines "Object Detection".
Object detection
In Object detection, the high level goal is to
Locate objects in rectangle bounding boxes, and identify the coordinates in the images
Estimate the likelihood of objects in the bounding boxes, and usually assign the class of the highest probability to the object.
Modern deep learning models, two schools of thinking have emerged in literature for Object Detection tasks, and they are:
Faster RCNN
Evolution: RCNN->SPP-Net -> Fast RCNN -> Faster RCNN
Key features:
Use regional proposal network sharing same conv layers with detectors;
Use the “attention” mechanism;
Use multi-task loss.
Single Shot Detector
Evolution: DNN based regression, MultiBox, AttentionNet, G-CNN -> Yolo, SSD
Key features:
A one-step methodology framework based on global regression/classification, mapping straightly from image pixels to bounding box coordinates and class probabilities, can reduce time expense
Both of these approaches are often used to achieve such goals, and both employ the Convolutional Neural Network (CNN) architecture. The following image is an example of such architecture.

source: Neurohive.io
To extremely simplify the concept, these architecture have 3 main components:
Convolutional layers to discover features
Max pooling layers to reduce dimension
Fully connected layers at the end with softmax to classify the object
As number three is easier to understand for most data scientists if they already have experience with classification; we have focused on unpacking number 1 and 2 with simplified examples.
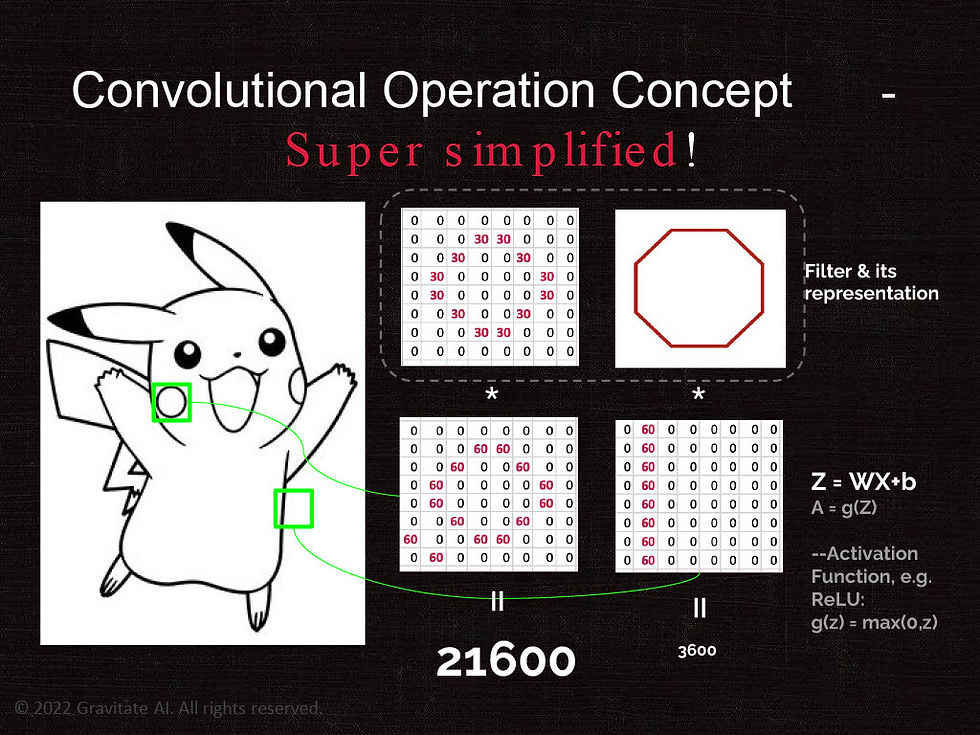
Convolutional Operation Concept
In the example below, we use an octagon "filter", which approximates a circle. The filter is represented by numbers in a matrix. Let's assume the white space is represented by zero and the line is represented by a number 30. (Please not that in reality, the numbers are different, and colored images has RGB three channels, hence 3 matrices.)
This filter is sliding down from left to the right, top to down of the image of Pikachu, like a piece of small glass on top of the picture. Where ever the piece of glass stops, it looks at the matrix of the image behind it, and the multiplies it (with a dot product). So image the piece of glass is around the top left corner of the image, where all element of the image are zeros, the dot product is zero. But when the glass moved to Pikachu's face, where the circle is, it found a pattern similar to the filter's octagon, and the dot product becomes very large, as 21,600 in this example! At that moment, we say it is "activated", meaning the pattern is discovered. So the AI found the pattern of the circle on Pikachu by using a similar shape to scan the picture!
The same trick is applied with many filters with different shapes / patterns, and the AI discover more such patterns in each convolutional operation. We like to think at the beginning of the layers, the AI discovers more general patterns, then the layers get deeper, the AI learns more specific patterns, which eventually leads to the specific object.
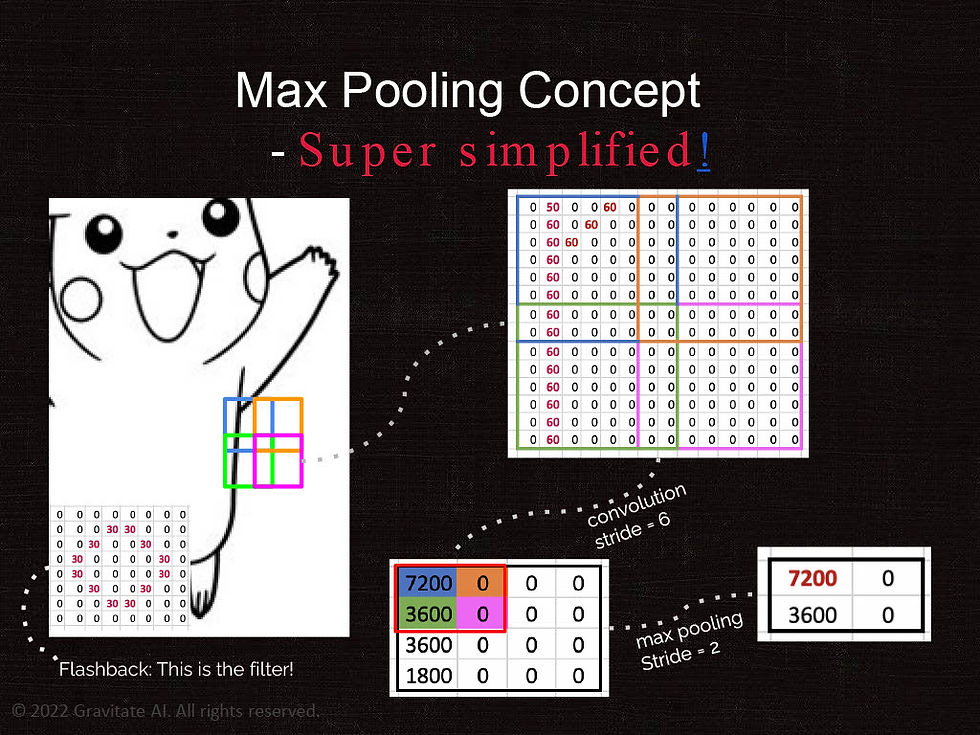
Max Pooling Concept
If the "convolutional" operation is the strategic part of the learning process, then the "max pooling" operation is more tactical. It is mainly to do dimension reduction. Our example is extremely simplified.
In reality, each digital image can be made up by a lot numbers! A small image of 512x512 resolution has 262,144 numbers in each color channel. A such color image with RGB three channels then ends up with 786,431 numbers! With all these layers of calculations, things go crazy fast. That is where max pooling comes in -- to "shrink" images to something smaller while try not to lose the patterns we want. In the example below, we look at the side of Pikachu's body. Then we divide that matrix to 4 areas with four different colors -- they overlap in this example. We can then simply average all the numbers in each square to one number.
The end result is we shrink the 14x14 square with 196 numbers to 4 numbers! That is a dramatic reduction for computation. Research and applications show these max pooling operations significantly reduce the computation burden, while still reserving the patterns for the convolution operations.
With some of these understandings, we are eager to get our hands on some real data and coding!
Deciding which framework to use
We can find many choices with narrowing gaps in popularity today. A quick search on Google Trend shows PyTorch, TensorFlow and Keras still lead the way.
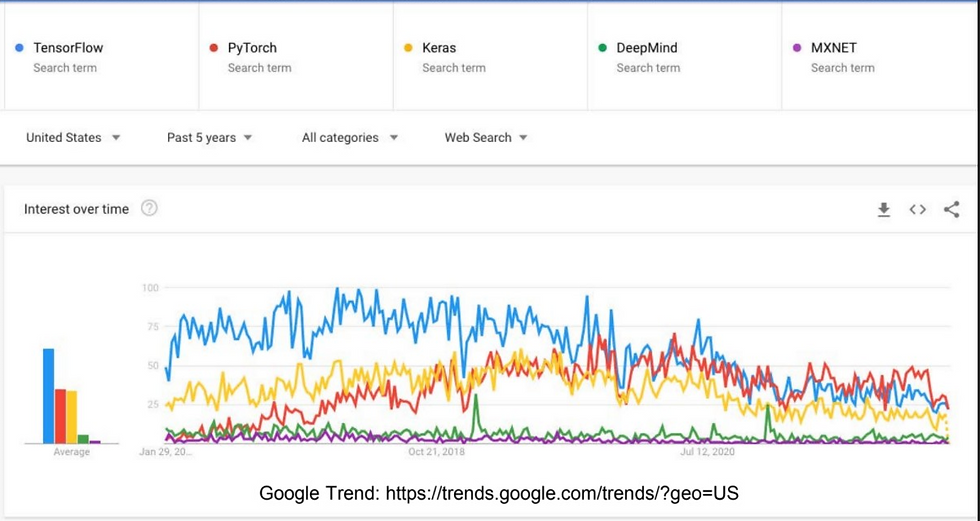
Source: Google Trend
About three years ago, we gathered some Pokemon images and labeled them ourselves. We are happy to share with you! At that time, we used the low level Tensorflow APIs to train the model and applied transfer learning. Then we used Tensorboard to evaluate the models.
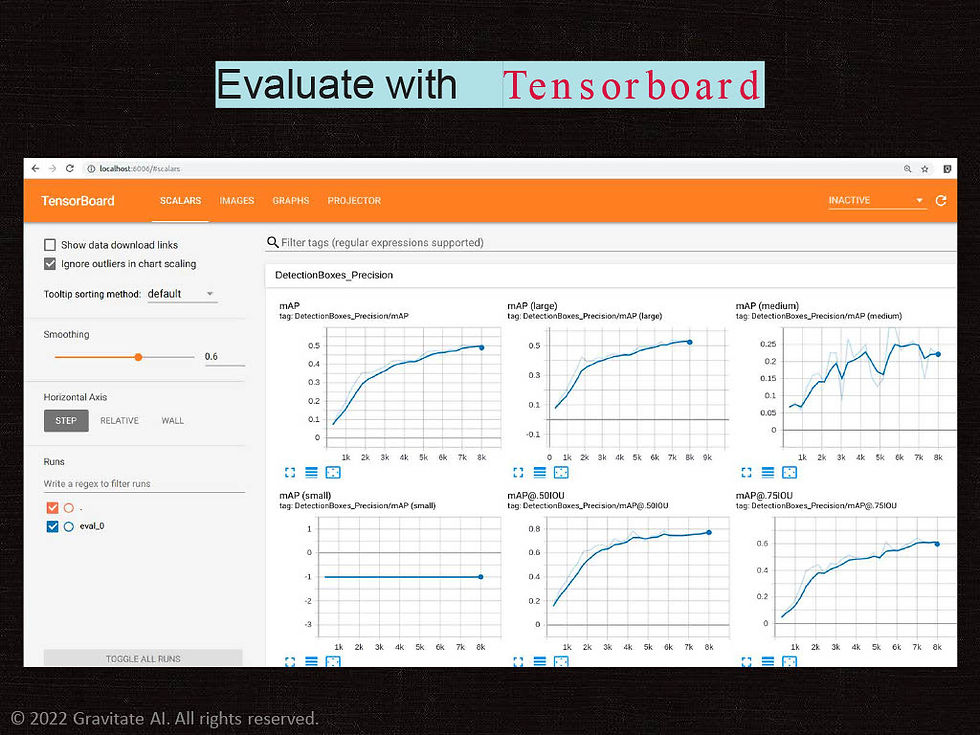
Today, we tried Tensorflow + Keras and the user experience has become much smoother!
We still use Tensorboard, as it is such a great tool to evaluate these deep learning models. We want to try PyTorch and other frameworks, but first, please let us know what you have tried. We invite anyone to come share learning with us on our linked in page.
To get you started, we are happy to share the data and our current base code with you here. Please let us know how you improved it.
Closing thoughts
Remember how we talked about children and AI learning? They have some remarkably similar aspects, however there is a huge difference!
For a child, they might take a couple times to learn how a Pikachu looks, but for AI, it might take thousands of images or more! Even with transfer learning, it took a few hundred images to get to a decent result. (Check out The Moravec’s Paradox).
We know so little about human brains, and they are marvelous. This poses a frontier challenge for AI -- how can we get AI to be more intelligent, instead of relying on brutal force with massive data input.
Gravitate strives to advance such technologies through working in partnership with our communities, and of course, to keep having fun while we learn!
If you're facing an AI challenge, we'd love to help. You can schedule a free introduction call any time.

Comments